Abstract
There are two reasons to run a model on infrastructure you own instead of calling an API: your data isn't allowed to leave, or at high enough volume it costs less. Enterprises weighing that choice face three options: self-host open weights, call the same weights on a managed provider (Amazon Bedrock), or pay for a frontier model. We built one workload, one serving and scoring harness, and held everything constant except the substrate, so each comparison isolates who runs the model and on what. The workload is the document pipeline this architecture targets: structured field extraction from invoices and claims (520 documents, deterministic per-field F1 against ground truth) and retrieval-augmented question answering over a 2,686-document financial-regulation corpus (226 questions, scored by one independent fixed judge that sees the retrieved context, validated against a human anchor). We evaluated nine open-weight families (Qwen3-VL-235B, Llama-4-Scout, GLM-4.7, Kimi-K2.5, DeepSeek-V3.2, GLM-5/5.2, the self-host-only Ornith-1.0-397B, the self-host-only 560B hybrid Mamba-MoE Nemotron-3-Ultra-550B, and the self-host-only 1.6T DeepSeek-V4-Pro) and two frontier models (Claude Opus 4.8, Sonnet 4.6) across self-hosted vLLM, Bedrock, and direct-API substrates. Three findings hold: (1) substrate-invariance, the same weights produce the same quality whether we serve them or Bedrock does, within confidence intervals, on every axis; (2) the frontier quality premium is confined to extraction on the hardest (commercial) degraded layouts and does not transfer to grounded RAG, where the whole lineup, frontier included, lands in one overlapping 80-86% band; (3) self-hosting wins on cost-per-token at high utilization for most of the lineup, with reasoning models the exception. Everything was measured on synthetic data, inside one VPC, and is reproducible from the open repository.
1. Background and objective
This is the reference architecture we built for workloads where the data can't leave or the volume makes self-hosting cheaper, and the measurements that show when each reason holds. It runs inside the customer's AWS account, with no third-party data egress. The infrastructure, the applications, and the benchmark harness are open.
1.1 The architecture
The stack is six layers, all inside one VPC. From the bottom: a platform layer (EKS with Karpenter, which provisions GPUs on demand), a data layer (S3, a Postgres vector store, and document parsing that stays on the network), the model-serving layer (vLLM running the open-weight model on a GPU, with the embedding and reranking models on cheaper CPU), the applications, a guardrails-and-evaluation layer, and the interface. Security and observability run across all six.

Model weights are downloaded once, at build time, into a storage bucket in the customer's account. After that, nothing on the path that serves a request leaves the VPC.
1.2 Objective and hypothesis
Buyers ask a concrete question: how much do I give up by self-hosting an open-weight model instead of just calling Bedrock or just using the frontier? Answering it requires holding the model and the workload fixed and varying only the substrate. We test one hypothesis, substrate-invariance: identical weights yield identical task quality regardless of who serves them, and, having established that the harness is calibrated, we quantify the quality, speed, and cost differences that distinguish the three options. Every figure below was measured on synthetic data (generated medical claims and commercial invoices, not real documents) so the benchmark can be published and reproduced. Where a result isn't final, the text says so.
2. Methods
2.1 Experimental design
One workload, one harness, three substrates. Every request (self-hosted, managed, or frontier) routes through the same gateway, which performs identical retrieval, prompting, vision routing, and scoring. The only manipulated variable is the substrate.
| Layer | Substrate | What it isolates |
|---|---|---|
| A, Sovereign self-hosted | our vLLM on rented GPUs, in-VPC | open weights re-run on our stack |
| B, Managed | the same family/checkpoint on AWS Bedrock | our serving vs the provider's, same weights |
| C, Frontier | Claude Opus 4.8 / Sonnet 4.6, via Bedrock and direct Anthropic | the ceiling, inside AWS's walls and out |
A vs B is the calibration check (same weights, two operators). B vs C is the open-vs-frontier gap. A leaderboard that pits our run of a model last quarter against Bedrock's run of a newer version this quarter isn't a fair test, the weights moved underneath it, so we refreshed our self-hosted lineup to the exact current-generation checkpoints Bedrock serves, and run the identical weights both ways.
2.2 Models under test
| Family | Params | Self-host precision / hardware | Managed |
|---|---|---|---|
| Qwen3-VL-235B | 235B | FP8, 8×H200 (TP=8) | Bedrock |
| Ornith-1.0-397B (self-host only) | 397B MoE | BF16, 8×H200 (TP=8) | , |
| Llama-4-Scout (same-weights pair) | 109B MoE | BF16, 8×H100 (TP=8) | Bedrock |
| GLM-4.7 | , | FP8, 8×H100 (TP=8) | Bedrock |
| Kimi-K2.5 | , | INT4 (native), 8×H200 (TP=8) | Bedrock |
| DeepSeek-V3.2 | , | FP8 (official), 8×H200 (TP=8) | Bedrock |
| Nemotron-3-Ultra-550B (self-host only) | 560B MoE | NVFP4, 8×H100 (TP=8) | , |
| DeepSeek-V4-Pro (self-host only) | 1.6T MoE | FP4+FP8, 8×H200 (TP=8) | , |
| GLM-5 / GLM-5.2 (family pair) | 745 / 753B | FP8, 8×H200 (TP=8) | Bedrock (GLM-5) |
| Claude Opus 4.8 (frontier) | , | , | Bedrock + direct |
| Claude Sonnet 4.6 (frontier) | , | , | Bedrock + direct |
Every self-hosted model followed the same serving ladder, and the comparison set the format. Where Bedrock lists the same weights, we pair the two and serve at the precision the managed side runs, so the only variable is who serves the model and not the format: Qwen3-VL, GLM-4.7, and DeepSeek-V3.2 run FP8 to match Bedrock rather than the higher-precision BF16, Llama-4-Scout is the strict same-weights pair with the identical checkpoint both ways, Kimi-K2.5 runs its native INT4 on both sides, and GLM-5/5.2 is a family pair rather than same-weights (Bedrock's GLM-5 against our half-version-newer GLM-5.2). Where Bedrock has no listing there is nothing to match, so the model is a self-hosted standalone served in the best build that fits one box: Ornith-1.0-397B, Nemotron-3-Ultra-550B, and DeepSeek-V4-Pro. Every serve runs on a single 8-GPU node under pinned stable vLLM v0.23.0.
When a model cannot take that path, we make the smallest change that keeps it on one box, staying on the same pinned engine, and we name it. Two models needed one. Nemotron-3-Ultra-550B is about 1.1 TB at full precision, too large for one node, so we serve its NVFP4 build on a single 8-GPU H100 box through vLLM's Marlin software fallback: Hopper reads the 4-bit weights for the memory saving and does the math at 8-bit. DeepSeek-V4-Pro ships as a ~865 GB FP4+FP8 mix that fits one 8-GPU H200 box, but the pinned stack's default kernels reject its block-scaled FP8; one setting (DeepGEMM for its UE8M0 scale) serves it, and its FP4 experts take the same Marlin path on Hopper. Both deviations cost throughput, which is why they sit on the expensive side of the cost table and DeepSeek-V4-Pro is the priciest model we serve (§3.5). A small dev-tier vision model, Qwen2.5-VL 7B on a single L40S (with a 72B reference), anchors the low end of the cost and routing analysis below.
2.3 Task 1, Structured document extraction
Goal. Read a claim or an invoice and pull out the structured fields (patient, provider, amounts, identifiers) as JSON, then score each field against the known-correct value.
Data. Two synthetic corpora with machine-emitted gold labels, each rendered at increasing real-world difficulty:
- Medical claims (Synthea, MITRE): 400 documents → CMS-1500 / EOB / medical-invoice layouts. Eight scored fields:
patient_name, payer_name, provider_name, provider_npi, service_date, total_billed, balance_due, num_line_items. Three tiers (134 / 133 / 133): clean-digital (PDF with a text layer), scanned-clean (image, no text layer), scanned-degraded (image + scan wear). - Commercial invoices (FATURA): 120 documents, real invoice layouts with synthetic content, 50 templates. Five scored fields:
invoice_number, invoice_date, due_date, total, buyer_name. Two tiers (60 / 60): scanned-clean, scanned-degraded.
The five scored fields for the commercial invoice pictured below, its gold record:
{"invoice_number": "2970-559", "invoice_date": "23-Jan-2002",
"due_date": "06-Dec-2018", "total": "828.69", "buyer_name": "Alexander Williams"}
Difficulty tiers, what keeps the benchmark representative. Each document goes through three tiers: clean digital (the original file, perfect text), clean scan, and degraded scan, skewed, blurred, downscaled, and JPEG-compressed, the way a fax or a phone photo arrives, produced deterministically per seed. A degraded image has no text layer, so it forces the vision path (reading pixels) rather than a pristine digital parse. The hardest tier is the headline number, because it's the one that looks like a real intake queue. Text-only models (Kimi, DeepSeek, GLM-4.7, GLM-5.2) have no vision path and are evaluated only on the clean-digital tier; vision models (Qwen3-VL, Llama-4-Scout, Opus, Sonnet) run all image tiers. One caveat: the synthetic documents share structure within each family, so they vary less than real-world paperwork, read the scores as a comparison between models, not a prediction for your own corpus.
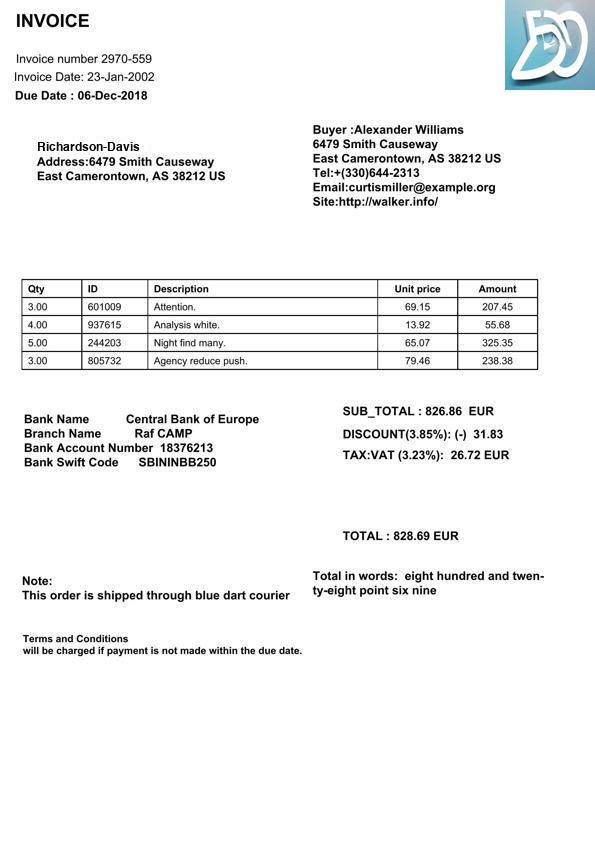
Clean scan

Degraded scan, same invoice
Prompt (verbatim, medical track; temperature 0, JSON-object mode):
System: You extract structured data from a medical claim/invoice. Return ONLY a JSON object with exactly these keys: patient_name, payer_name, provider_name, provider_npi, service_date (YYYY-MM-DD), total_billed (number), balance_due (number), num_line_items (integer). Use null for any field not present. User: INVOICE:\n<document text or image>
Scoring (deterministic, per field). A field counts as correct under type-appropriate matching: money within $0.01; counts as exact integers; names by alpha-token containment (so Dr. Rhett Smith · Cardiology matches gold Rhett Smith, the rendered "Name · Specialty" and Synthea's numeric suffixes are not extraction errors); identifiers and dates by normalized containment. F1 = correct fields / (documents × fields), reported per tier with a Wilson 95% confidence interval. The headline number is the hardest tier (scanned-degraded, abbreviated med-deg / com-deg).
2.4 Task 2, Retrieval-augmented QA (sovereign RAG)
Goal. Answer a financial-regulation question grounded only in retrieved passages, with citations or an explicit refusal.
Corpus and pipeline (all in-VPC). 2,686 public US financial-regulation documents (CFPB consumer-finance reports and Federal Register rules, e.g. the Consumer Credit Card Market Report, CARD Act notices). Ingestion: chunk (1,400 chars, 200 overlap) → embed (TEI / BGE, 768-dim) → store in Postgres + pgvector. Query: embed → cosine top-5 → prompt → cited answer.
An example evaluation question (from a set of 250): "What act requires the CFPB to review the consumer credit card market?", reference answer: "The Credit Card Accountability Responsibility and Disclosure Act of 2009 (CARD Act)…"
Prompt (verbatim; temperature 0, top-5 context):
System: You answer strictly from the provided CONTEXT about financial regulation. Cite the sources you use with bracketed numbers like [1]. If the answer is not in the context, say exactly: "I don't know based on the provided documents." User: CONTEXT:\n[1] (source: …)\n…\n\nQUESTION: <q>\n\nAnswer with citations:
Scoring needs one fixed judge, and here is why. The tempting shortcut is to let each model grade its own answers, but that breaks the comparison: a stronger model grades harder and gives itself a lower score. We measured it, the same pipeline scored 38.8% when a 7B model graded it and 30.0% when a 72B model graded the exact same answers. So RAG answers are graded by an LLM-as-judge held fixed across all models: Qwen2.5-VL-72B-Instruct on pinned vLLM v0.23.0. The judge sees (question, reference, retrieved context, candidate) and returns a strict verdict. Showing the judge the context matters: our first rubric hid it, and that judge rejected correct answers whose grounded elaboration went beyond the terse reference. A 50-answer human anchor measured the damage (human 98% correct, blind judge 65%, 17 wrongful rejections); the context-aware rubric agrees with the human on 47 of 47 judgeable items with zero wrongful rejections:
System: You are a strict grader for a financial-regulation QA system. Compare the
CANDIDATE answer to the REFERENCE answer for the QUESTION. Return JSON
{"correct": true|false, "score": 0-100, "reason": "..."}. correct=true only if the
candidate is factually consistent with the reference and does not add unsupported
claims. Brevity is fine.
To avoid confounding the judge with the model under test, answers are collected first and judged in a separate pass by the one fixed judge. Accuracy = % correct, with a Wilson 95% confidence interval (n = 226; the question set is entity-anchored so every question identifies its source document, and deduplicated; see 4.5).
2.5 Speed and cost
- Latency (managed / frontier): per-request end-to-end through the gateway, reported as p50/p95.
- Throughput (self-hosted): peak aggregate tokens/s under a 64-concurrent load generator, a throughput you own, not a single-request latency. The two speed metrics measure different things; we report each where it applies. (When you push a managed API, the ceiling shows up as added latency, the provider queues you rather than returning an error; you can make managed throughput fixed by buying dedicated capacity, e.g. Bedrock Provisioned Throughput, but that turns the bill back into a by-the-hour number that looks a lot like self-hosting. We measured the on-demand, pay-per-token path, because that's where a team comparing "just call the API" starts.)
- Cost, managed: provider list price, $ per million output tokens (Anthropic first-party list; OSS-on-Bedrock from the AWS Price List API, us-west-2 on-demand).
- Cost, self-hosted: measured spot $/hr ÷ peak aggregate tok/s = $ per million output tokens, a best case (peak utilization, point-in-time spot). The two cost bases differ on purpose: managed bundles the operator's margin; self-host is raw rental you operate.
2.6 Controls and reproducibility
Temperature 0 everywhere, including the managed providers (an asymmetry we found and fixed: earlier managed runs sampled at provider defaults); one retrieval pipeline; one fixed judge; identical prompts and concurrency profiles. Data is fully synthetic or public-domain, deterministic given pinned seeds (Synthea v4.0.0 / seed 1337; FATURA at a pinned revision; degradation seeded per item index), so a clean checkout regenerates byte-identical documents and gold. A completeness guard fails any run whose section completes under 80% of attempts, so a silent mass-drop cannot masquerade as a passing score.
3. Results
3.1 Per-model scorecard (the headline)
Each model on every axis, self-hosted and managed. Extraction shows the hardest applicable tier; RAG is fixed-judge accuracy on metric v2 (n = 226; see 3.4 and 4.5); speed is latency p50 for managed and peak throughput for self-host; cost is $ per million output tokens.
| Model | Substrate | Extraction¹ | RAG² | Speed³ | $/M-out⁴ |
|---|---|---|---|---|---|
| Qwen3-VL-235B | Self-host (FP8, 8×H200) | 97.9 / 83.7 | 85.0 | 3,838 tok/s | $1.30 |
| Bedrock | 97.9 / 83.7 | 85.4 | 2.9 s | $2.66 | |
| Ornith-1.0-397B (self-host only) | Self-host (BF16, 8×H200) | 99.7 / 81.0 | 85.0 | 2,710 tok/s | $1.99 |
| Llama-4-Scout ⁵ | Self-host (BF16, 8×H100) | 91.3 / 72.3 | 83.2 | 3,927 tok/s | $1.01 |
| Bedrock | 91.3 / 71.7 | 83.2 | 0.8 s | $0.66 | |
| GLM-4.7 | Self-host (FP8, 8×H100) | 99.3 (clean) | 83.6 | 3,120 tok/s | $1.27 |
| Bedrock | , | 80.5 | 1.3 s | $2.20 | |
| Kimi-K2.5 | Self-host (INT4, 8×H200) | 100.0 (clean) | 82.3 | 2,295 tok/s | $2.18 |
| Bedrock | , | 80.1 | 1.4 s | $3.00 | |
| DeepSeek-V3.2 | Self-host (FP8, 8×H200) | 99.4 (clean) | 84.5 | 1,403 tok/s | $3.56 |
| Bedrock | , | 81.0 | 1.8 s | $1.85 | |
| Nemotron-3-Ultra-550B (self-host only) | Self-host (NVFP4, 8×H100) | 98.3 (clean) | 83.2 | 2,006 tok/s | $1.96 |
| DeepSeek-V4-Pro (self-host only) | Self-host (FP4+FP8, 8×H200) | 98.4 (clean) | 80.1 | 516 tok/s | $11.71 |
| GLM-5.2 / GLM-5 ⁶ | Self-host GLM-5.2 (FP8, 8×H200) | 99.3 (clean) | 84.5 | 1,357 tok/s | $3.69 |
| Bedrock (GLM-5) | 99.4 (clean) | v2 pending | 2.4 s | $3.20 | |
| Opus 4.8 (frontier) | Bedrock | 99.4 / 93.7 | 82.7 | 4.7 s | $25.00 |
| Anthropic direct | 99.7 / 94.0 | 81.4 | 2.8 s | $25.00 | |
| Sonnet 4.6 (frontier) | Bedrock | 99.4 / 88.7 | 83.2 | 3.5 s | $15.00 |
| Anthropic direct | 99.5 / 89.3 | 82.7 | 3.6 s | $15.00 |
¹ Vision models: medical-degraded / commercial-degraded F1 (hardest scanned tiers). Text-only models: clean-digital F1 (their only tier, no vision path). ² RAG fixed-judge accuracy; read the cluster, not the rank (§4.2). ³ Managed = per-request latency p50; self-host = peak aggregate throughput at 64-concurrent, different metrics (§2.5). ⁴ $/M output; managed list price, self-host = spot $/hr ÷ peak tok/s (best case). ⁵ Strict same-weights pair. ⁶ Family pair, not same-weights.
3.2 Extraction quality, by tier
On the hardest tier, degraded scans, the picture splits by document type. On medical, the whole vision field now saturates (Opus and Ornith at 99.4–99.7, Qwen3-VL 97.9), so the tier no longer separates the models; the frontier's lead survives only on commercial layouts, where Opus leads the best open model by ~10 points. The natively-multimodal Scout is the weakest on both:
| Model | Substrate | med-deg | com-deg |
|---|---|---|---|
| Opus 4.8 | Bedrock | 99.4 | 93.7 |
| Opus 4.8 | Anthropic direct | 99.7 | 94.0 |
| Sonnet 4.6 | Bedrock | 99.4 | 88.7 |
| Ornith-1.0-397B | Self-host | 99.7 | 81.0 |
| Qwen3-VL-235B | Self-host | 97.9 | 83.7 |
| Qwen3-VL-235B | Bedrock | 97.9 | 83.7 |
| Llama-4-Scout | Self-host | 91.3 | 72.3 |
Field-level F1 against gold labels. Text-only models on their clean-digital tier: Kimi-K2.5 100.0, DeepSeek-V3.2 99.4, GLM-4.7 99.3, GLM-5.2 99.3, DeepSeek-V3.1 99.1, DeepSeek-V4-Pro 98.4, Nemotron-3-Ultra 98.3 (self-host); GLM-5 99.4 (Bedrock). The clean-digital tier is saturated across the lineup: the medical provider_npi field that used to drag every score was a gold-data artifact rather than a model weakness (§4.5). On hard documents a bigger model narrows the gap but doesn't close it; cleaning up the image first (de-skew, sharpen) often does more, for less.
3.3 A vision "penalty" on clean text that turned out to be a gold bug
An earlier edition reported that a vision-capable model read clean digital text worse than its same-size, same-price text-only twin (Qwen2.5-7B 99% vs Qwen2.5-VL-7B 87.5%), and we routed the pipeline around it. It was an artifact of the provider_npi gold bug (§4.5): the vision model had to OCR a 36-character UUID off a rendered page while the text model copied it from the text layer, and that one field of eight, measured on a 12-document early smoke, produced almost all of the gap. On the corrected gold at proper scale (~130 docs/tier) the penalty disappears: text-only Qwen2.5-7B 96.9%, the vision sibling reading the page as an image 97.7%, a fraction of a point apart. Route-by-input still holds (digital files to the text path, scans and photos to the vision path), but the reason is efficiency: read a text layer instead of paying a model to OCR it, since the corrected numbers show no accuracy cost on clean text. Scale is a separate question, and it still pays only where vision is hard: a 72B sibling ties the 7B on clean and leads by 1–2 points on degraded medical, reaching just 74.5% on the hardest commercial scans.
3.4 Retrieval quality (all models, n = 226, context-aware fixed judge)
| Model | Self-host | Bedrock / frontier |
|---|---|---|
| DeepSeek-V3.1 | 86.3 [81.2, 90.2] | , |
| Qwen3-VL-235B | 85.0 [79.7, 89.0] | 85.4 |
| Ornith-1.0-397B (self-host only) | 85.0 [79.7, 89.0] | , |
| DeepSeek-V3.2 | 84.5 [79.2, 88.6] | 81.0 |
| GLM-5.2 | 84.5 [79.2, 88.6] | , |
| GLM-4.7 | 83.6 [78.2, 87.9] | 80.5 |
| Nemotron-3-Ultra-550B (self-host only) | 83.2 [77.8, 87.5] | , |
| Llama-4-Scout | 83.2 [77.8, 87.5] | 83.2 |
| Kimi-K2.5 | 82.3 [76.8, 86.7] | 80.1 |
| DeepSeek-V4-Pro (self-host only) | 80.1 [74.4, 84.8] | , |
| Opus 4.8 | , | 82.7 / 81.4 |
| Sonnet 4.6 | , | 83.2 / 82.7 |
Every confidence interval overlaps: the whole lineup, frontier included, is one statistical cluster at 80-86%. Read the cluster, not the rank; no per-model ordering in this table is meaningful. These are metric-v2 numbers (context-aware judge, entity-anchored questions, temperature 0 on every substrate); the v1 numbers this table previously carried (23-43%) were an artifact of the metric and are retired. The correction is described in 4.5. Opus and Sonnet show Bedrock / direct-API; GLM-5 on Bedrock is pending its v2 pass.
3.5 Speed and cost
Managed latency p50 (p95 where notable), seconds: Scout 0.8 · GLM-4.7 1.3 · Kimi 1.4 · DeepSeek 1.8 · GLM-5 2.4 (p95 24.7, thinking tail) · Qwen3-VL 2.9 · Sonnet 3.5 · Opus-direct 2.8 vs Opus-Bedrock 4.7 (p95 ~11.6). Self-hosted peak throughput, tok/s: Scout 3,927 · Qwen3-VL 3,838 · GLM-4.7 3,120 · Ornith 2,710 · Kimi 2,295 · Nemotron 2,006 · DeepSeek 1,403 · GLM-5.2 1,357 · DeepSeek-V4-Pro 516 (small dev-tier Qwen2.5-VL 7B: 2,375 on one L40S).
Cost. Frontier output tokens run 8–38× the OSS-on-Bedrock models: Opus $25/M, Sonnet $15/M vs $0.66–$3.20/M. Self-hosting the same open weights at peak utilization beats Bedrock for most of the lineup (GLM-4.7 $1.27 vs $2.20, Qwen3-VL $1.30 vs $2.66, Kimi $2.18 vs $3.00) but loses for DeepSeek-V3.2 ($3.56 self vs $1.85 Bedrock) and Llama-4-Scout ($1.01 self vs $0.66 Bedrock, dirt-cheap managed). Ornith-1.0-397B, self-hosted only, comes to $1.99/M: a reasoning model, but cheaper than the other two reasoning models (DeepSeek $3.56, GLM-5.2 $3.69) because its 2,710 tok/s throughput is about double theirs. Nemotron-3-Ultra-550B, also self-hosted only, comes to $1.96/M on 8×H100, though that runs its NVFP4 weights through a Marlin software fallback (no FP4 acceleration on Hopper), so a Blackwell box would beat it. DeepSeek-V4-Pro is the outlier at the top: the largest model in the set (1.6T), it serves only 516 tok/s and costs $11.71/M, about three times the next model, for three compounding reasons: its size, a reasoning model's long output chains, and the same Marlin-FP4-on-Hopper software path Nemotron uses. At more typical H200 spot it comes down to about $9.70/M but stays the costliest serve, and a Blackwell box built for its FP4 format would bring it well below that. You choose it for quality and pay for it in serving cost. The small dev-tier model serves a million tokens for about $0.22; against a typical small-model API near $0.30/M, self-hosting it pays off above about 150 million tokens a day, and below that the API is cheaper. Spot basis: 8×H100 (p5.48xlarge) $14.22/hr; 8×H200 (p5e.48xlarge) ~$18/hr, shortage-elevated on the run date. At the typical ~$14, the H200 self-host rows fall about a fifth.
3.6 Calibration check (A vs B)
The test of a fair harness: each self-hosted score should land on its managed twin. It does, on both axes.
- Extraction: Qwen3-VL identical to the decimal on both degraded tiers (medical 97.9 / 97.9, commercial 83.7 / 83.7). Llama-4-Scout (the identical checkpoint) matches on both vision axes: med-deg 91.3 vs 91.3, com-deg 72.3 vs 71.7.
- RAG (v2): every self-hosted score sits inside its managed twin's confidence interval; Scout, the exact-weights pair, is identical to the decimal (83.2 vs 83.2). Self-host comes in higher on three of five (DeepSeek +3.5, GLM-4.7 +3.1, Kimi +2.2, Qwen3-VL -0.4), all within noise; the Opus Bedrock-vs-direct gap (1.3 points, same model twice) is the natural yardstick for substrate noise.
Substrate-invariance holds. Same weights → same quality regardless of who serves them.
4. Discussion
4.1 The frontier premium is an extraction-on-degraded phenomenon
On commercial-degraded scans, Opus (94%) leads the best open model, Qwen3-VL-235B (83.7%), by about 10 points; Sonnet sits between (88.7%). On medical-degraded there is no longer a gap to speak of: once a gold-data bug was fixed (§4.5), the whole vision field saturates (Opus and Ornith at 99.4–99.7, Qwen3-VL at 97.9), so that tier no longer separates the models at all. What remains is the commercial premium, where Llama-4-Scout is the weakest vision extractor (72%): natively multimodal does not mean good at document vision. The bigger model helps on one thing: the long identifiers and account numbers on the harder commercial layouts, the strings that break up on a noisy image. So the case for paying 8–38× per token rests on one axis, extraction accuracy on hard degraded commercial layouts, and nothing else.
4.2 The premium does not transfer to RAG
Grounded QA lands in one 80-86% band across the entire lineup with overlapping confidence intervals: the frontier does not lead. This is the metric-v2 result, and it is stronger than the v1 version of this finding: v1's compressed 23-43% band left room to argue the eval could not separate models, and our own review confirmed that criticism (see 4.5). On the repaired metric, with a judge that sees the retrieved context and agrees with a human anchor on 47 of 47 items, and a question set where every item identifies its source document, the answer is unambiguous: open-weight models match the frontier on grounded regulatory QA. Sonnet's v1 "style penalty" disappeared once the judge could verify elaboration against the context; it now sits mid-band at 82.7-83.2. The remaining ~15-point gap to perfect is dominated by retrieval misses, not answer quality, so the next lever is recall, not a bigger generator. The practical reading stands: on RAG, choose by cost and latency, not by RAG rank.
4.3 Self-hosting economics: utilization and sovereignty, not a blanket win
Per output token at peak utilization, self-hosting beats Bedrock for most of the lineup, but not the cheap-on-Bedrock model (Scout) or the slow reasoner (DeepSeek). The lever is utilization: the self-host figures assume peak 64-concurrent throughput on shortage-elevated spot; average utilization is lower and shortage pricing inflates the H200 rows. The durable self-host arguments are therefore (1) cost at high, sustained utilization, and (2) sovereignty and data control, not a universal per-token saving. Reasoning models pay a throughput cost: DeepSeek-V3.2 (1,403 tok/s) and GLM-5.2 (1,357 tok/s) generate long chains per request, and DeepSeek-V4-Pro is the extreme case at 516 tok/s and $11.71/M, the throughput cost of reasoning compounded by size (1.6T). That is why the reasoning models are the priciest to self-host, and why a top benchmark score does not settle the deployment question on its own.
4.4 A trillion parameters no longer needs a cluster
Kimi-K2.5 is the interesting one, and it overturned our own assumption. At a trillion parameters we expected it to need more than one machine. It doesn't. The model ships as a natively four-bit checkpoint, its makers trained it to run at low precision, so the public weights are about 595 GB, not the two terabytes a trillion full-precision parameters would take. That fits on a single eight-GPU box with room to spare. So we serve it like everything else (one machine, rented by the hour) and it posted the highest extraction score of the open models we tested (a perfect 100% on clean digital) and sits in the lineup-wide retrieval band with everything else. DeepSeek-V4-Pro makes the same point at a larger scale: 1.6 trillion parameters, and it also serves on a single eight-GPU box. As a mixed 4-bit/8-bit build near 865 GB it needs the larger H200 machine, and it is expensive to run (§3.5), but it is one box, not a cluster. Two things follow. "Trillion-parameter" no longer means "needs a cluster." And the frontier model you rent from a cloud may be the very same compact four-bit checkpoint you could run yourself. Providers don't publish the precision they serve at, and for this model there is only one public version to compare against.
4.5 Threats to validity
- FATURA buyer-name gold bug (fixed). About 45–50% of
buyer_namegold values were the literal label "Bill to"; corrected and all managed models re-scored on the corrected 5-field gold. The fix raised commercial F1 across the board (e.g. Opus 92.9→93.7, Scout 66.2→71.7). - Medical
provider_npigold bug (fixed). The medicalprovider_npigold held the provider's internal Synthea record UUID rather than a standardized ten-digit NPI. Most models transcribed whatever string sat in that field and scored fine; a reasoning model (DeepSeek-V4-Pro) declined to emit a value it judged invalid, which surfaced the bug. We regenerated the gold with valid NPIs and re-scored all 21 models. Medical extraction rose across the board (e.g. Qwen3-VL 95.0→97.9, Llama-4-Scout 84.6→91.3, the text models to 98–100%) and the clean-digital tier now saturates, the numbers in this writeup are the corrected ones. Commercial and RAG were untouched by this fix. - RAG metric v1 (fixed; all RAG numbers re-based). The original RAG metric had two defects: the judge never saw the retrieved context (a 50-answer human anchor caught it rejecting 17 of 50 correct answers; human 98% vs judge 65%), and the question set held duplicated and under-specified questions (250 items, only 207 unique; 19 questions with conflicting gold answers). Both were repaired: entity-anchored deduplicated gold (n = 226), a context-aware judge validated at 47/47 against the human anchor, temperature 0 on managed providers (they had sampled at provider defaults, a comparability bug), and every judged artifact now records its judge deployment. All 23 columns were re-collected and re-judged in one pass; the v1 numbers (23-43%) are retired as non-comparable. The v1 defects deflated every model about 50 points and compressed the lineup into noise; per-model RAG ranks quoted from v1 were meaningless.
- Latency ≠ throughput: managed latency is best-effort per-request; self-host throughput is owned capacity. Reported on their own, never merged.
- GLM-5/5.2 is a family pair, not same-weights: do not read that row as a calibration check.
- Self-host $/M is best-case: peak utilization, point-in-time shortage-elevated spot. The numbers were measured on AWS; the platform runs the same on Azure and GCP, and equivalent results there are planned.
5. Conclusions
5.1 Best all-around
For a mixed enterprise document workload (scanned intake and grounded QA), the best all-around open-weight model is Qwen3-VL-235B. It is the only open model strong on both axes: best open document-vision extraction (matching its Bedrock twin to the decimal at 83.7% on degraded scans) and a competitive ~29–30% on RAG, at low cost ($1.30/M self-hosted, $2.66 Bedrock) and the highest open-model throughput tested (3,838 tok/s). If the workload is text-only (no scanned images), GLM-4.7 is the better all-rounder: top-cluster RAG (36.8% self-hosted), saturated clean-digital extraction (99.3%), the cheapest self-host ($1.27/M), and the fastest managed latency (1.3 s). If retrieval quality is the single thing that matters and the volume is bounded, DeepSeek-V4-Pro tops the RAG axis (40%), but at $11.71/M it is the most expensive open model to serve, a quality choice rather than a default. Pay for the frontier (Opus 4.8) only when degraded commercial-document extraction accuracy is the priority. That is now the one axis where its ~10-point lead and 8–38× cost are justified (medical extraction saturates across the open lineup).
5.2 Situational guide
| If your priority is… | Pick | Why (from the data) |
|---|---|---|
| Hardest scanned-document extraction accuracy | Opus 4.8 | 94% com-deg, ~10 pts over the best open model; the frontier premium is real here |
| Best open vision+text all-rounder | Qwen3-VL-235B | matches Bedrock to the decimal on extraction, ~30% RAG, $1.30 self, 3.8k tok/s |
| Text-only docs, best RAG + economics | GLM-4.7 | 36.8% RAG self, $1.27/M self, 1.3 s managed, 3.1k tok/s |
| Best retrieval quality, cost secondary | DeepSeek-V4-Pro | 40% RAG, top of the lineup, but $11.71/M (≈3× next) and the slowest to serve; a quality pick |
| Lowest cost / latency, clean inputs | Llama-4-Scout | $0.66/M Bedrock, 0.8 s, 3.9k tok/s, but weakest extraction (72% com-deg) |
| Clean docs, modest volume | small model on one GPU, or a managed API | $0.22/M self; under ~150M tokens/day the API is cheaper |
| Maximum data sovereignty | any self-host (Qwen3-VL / GLM-4.7 best value) | calibration proves self-host reproduces managed quality |
| Grounded RAG in particular | treat as a tie; choose on cost/latency | the ~30–33% cluster's intervals overlap, so RAG rank is not decisive |
5.3 Where this nets out
If your documents are clean and your volume is modest, a small model on one GPU is cheap and good enough, and under the break-even volume, a managed API or Bedrock-in-VPC is the cheaper choice. If your inputs are messy, a larger model is worth its cost on the hard fields, though none of them make degraded scans easy. And sometimes the reason to self-host has nothing to do with cost: the data cannot leave, which a dollars-per-token table does not capture.
The sovereign stack is not a quality compromise: on identical inputs it reproduces the managed provider's output on every axis. The real decision is an economic and operational one (utilization, latency profile, and data-control posture) and, for the single case of degraded-layout extraction, whether the frontier's accuracy edge is worth its premium. The point of running each model on Bedrock and beside the frontier is to let those tables say "just use Bedrock" or "just use Opus" out loud, in numbers, when that's the honest answer. A comparison you trust when it favors self-hosting is one that was willing to come out the other way.
Appendix: provenance & reproducibility
Runner: bench/managed-sweep.sh (+ job-quality-managed.yaml); self-host throughput via bench/loadgen.py. Scorer: bench/quality/score.py (+ judge.py, stats.py). Judge: Qwen2.5-VL-72B on vLLM v0.23.0. Data generators: data/synthea/, data/fatura/build.py, data/corpus/build.py; pins in data/README.md (Synthea v4.0.0 / seed 1337; FATURA pinned revision). Everything is in the open repository alongside the Terraform, the Helm charts, and the harness that produced these numbers.